简介
ELK 是一套完整的日志搜集和展示方案
包含:
ElasticSearch,它是一个实时的分布式搜索和分析引擎,它可以用于全文搜索,结构化搜索以及分析。它是一个建立在全文搜索引擎 Apache Lucene 基础上的搜索引擎,使用 Java 语言编写。
Logstash
数据收集引擎。它支持动态的从各种数据源搜集数据(如:读取文本文件),并对数据进行过滤、分析、丰富、统一格式等操作,然后存储到用户指定的位置,并将数据发送给ES。
Kibana 为 Elasticsearch 提供了分析和可视化的 Web 平台。它可以在 Elasticsearch 的索引中查找,交互数据,并生成各种维度表格、图形。
用途
日志分析并不仅仅包括系统产生的错误日志,异常,也包括业务逻辑,或者任何文本类的分析。而基于日志的分析,能够在其上产生非常多的解决方案,譬如:
问题排查:我们常说,运维和开发这一辈子无非就是和问题在战斗,所以这个说起来很朴实的四个字,其实是沉甸甸的。很多公司其实不缺钱,就要稳定,而要稳定,就要运维和开发能够快速的定位问题,甚至防微杜渐,把问题杀死在摇篮里。日志分析技术显然问题排查的基石。基于日志做问题排查,还有一个很帅的技术,叫全链路追踪,比如阿里的eagleeye 或者Google的dapper,也算是日志分析技术里的一种。
监控和预警:日志,监控,预警是相辅相成的。
关联事件:多个数据源产生的日志进行联动分析,通过某种分析算法,就能够解决生活中各个问题。比如金融里的风险欺诈等。这个可以可以应用到无数领域了,取决于你的想象力。
数据分析。
架构
最简单的架构
Logstash 通过输入插件从多种数据源(比如日志文件、标准输入 Stdin 等)获取数据,再经过滤插件加工数据,然后经 Elasticsearch 输出插件输出到 Elasticsearch,通过 Kibana 展示。
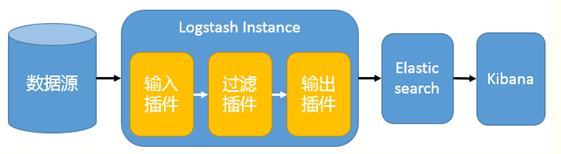
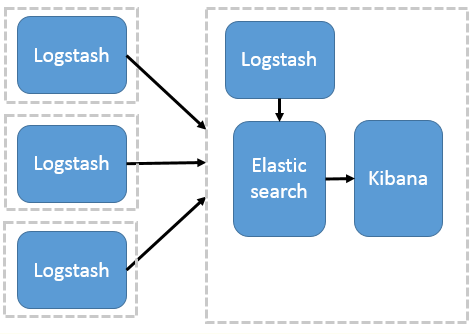
以Logstash 作为日志搜集器
这种结构因为需要在各个服务器上部署 Logstash,而它比较消耗 CPU 和内存资源,所以比较适合计算资源丰富的服务器,否则容易造成服务器性能下降,甚至可能导致无法正常工作。
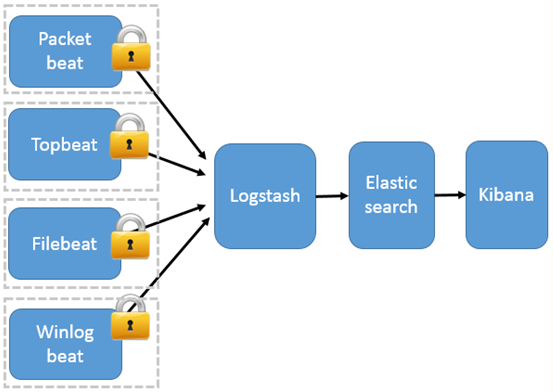
以Beats 作为日志搜集器
这种架构引入 Beats 作为日志搜集器。目前 Beats 包括四种:
- Packetbeat(搜集网络流量数据);
- Topbeat(搜集系统、进程和文件系统级别的 CPU 和内存使用情况等数据);
- Filebeat(搜集文件数据);
- Winlogbeat(搜集 Windows 事件日志数据)。
Beats 将搜集到的数据发送到 Logstash,经 Logstash 解析、过滤后,将其发送到 Elasticsearch 存储,并由 Kibana 呈现给用户。
这种架构解决了 Logstash 在各服务器节点上占用系统资源高的问题。相比 Logstash,Beats 所占系统的 CPU 和内存几乎可以忽略不计。另外,Beats 和 Logstash 之间支持 SSL/TLS 加密传输,客户端和服务器双向认证,保证了通信安全。
因此这种架构适合对数据安全性要求较高,同时各服务器性能比较敏感的场景。
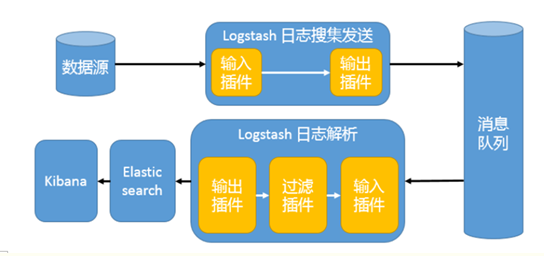
引入消息队列模式
logstash从各个数据源搜集数据,不经过任何处理转换仅转发出到消息队列(kafka、redis、rabbitMQ等),后logstash从消息队列取数据进行转换分析过滤,输出到elasticsearch,并在kibana进行图形化展示
模式特点:这种架构适合于日志规模比较庞大的情况。但由于 Logstash 日志解析节点和 Elasticsearch 的负荷比较重,可将他们配置为集群模式,以分担负荷。引入消息队列,均衡了网络传输,从而降低了网络闭塞,尤其是丢失数据的可能性,但依然存在 Logstash 占用系统资源过多的问题
工作流程:Filebeat采集 —> logstash转发到kafka —> logstash处理从kafka缓存的数据进行分析 —> 输出到e s—> 显示在kibana